
上一篇 FFmpeg 入门与实践 002
压缩
可以用压缩比 \(r\) 描述压缩性能:
\[ r = \frac{B_0}{B} \]
其中,\(B_0\) 为压缩后平均比特率,\(B\) 为压缩前平均比特率。
对于无损压缩,理论最低的平均比特率为源信号的熵(Entropy)。以 \(H\) 代表源信号的熵,可得:
\[ R = B_0 - H \]
\(R\) 为统计学冗余(Statistical Redundancy),即,统计学意义上,编码器处理原始信号所产生的冗余。
这个式子不难理解,熵的信息学定义是整个系统的平均信息量,若信息量的定义为 \(-\log_2x\)(即系数为 \(-1\),\(\log\) 底数为 \(2\)),那么信息量的单位,就是 \(\text{Bit}\)。同时,熵的单位也为 \(\text{Bit}\)。自然,\(B_0\) 就能和 \(H\) 相运算。
而无损压缩的终极目标,就是使 \(R=0\),亦即 \(B_0 = H\)。
因为无损压缩并不丢失信息,所以,压缩率 \(r\) 十分有限。如果 \(r\) 能达到 \(2:1\),已经是相当高的水准了。

同时,有损压缩还会丢失人类不可查觉的信息,即知觉不相关信息(Perceptual
Irrelevance),进一步提高压缩比。下图中的量化
Quantization
即指这一过程(这只是一个抽象描述,是一种过度简化,实际过程更复杂)。

量化
去除知觉不相关的基本方法是量化(Quantization),即以较低精度表示源信号样本。例如,整数值 \(1000\),在二进制下储存它需要 \(10 \, \text{Bit}\)。如果用量化步长为 \(9\) 的量化器(SQ,Scalar Quantizer)处理,可得:
\[ 1,000 \div 9 \approx 111 \]
现在,它只需要 \(7 \, \text{Bit}\)。同时,在解码时,可以被重构为:
\[ 111 \times = 999 \]
量化误差(Quantization Error)为:
\[ 1,000 - 999 = 1 \]
试想一下,有 \(1,000\) 个这样的数据。影响是很大的。这一步的压缩比 \(r\) 能达到 \(10:7\).
同时,因为量化误差,有损压缩是不可逆的。通过合理调整量化步长,可以降低量化误差。
以上仅为最简单的一种量化,实际情况要复杂得多。
熵编码
熵编码是最常用的无损压缩方法。是去除统计学冗余的常用方法。Huffman 编码、算术编码都是熵编码。几乎所有现代通用无损压缩算法,例如 zip、LZMA、rar、bzip2 等,都要么基于 Huffman 编码,或是参考其理论。
熵编码的核心思想是建立字典,用短编码表示经常出现的值。
根据 Shannon 信源编码定理,一个符号最佳码长为 \(- \log_bP\),其中 \(b\) 其中是码的数目,\(P\) 是输入符号出现的概率。也就是说,出现概率越高,就应使用更短的编码。
以下图为例:
| 样本 | 概率 | 熵编码 |
|---|---|---|
| \(0\) | \(1/2\) | \(1\) |
| \(1\) | \(1/4\) | \(01\) |
| \(2\) | \(1/8\) | \(001\) |
| \(3\) | \(1/8\) | \(0001\) |
本表列出了 4 个样本,和对应的出现概率。假设我们表示一个样本需要 \(2 \, \text{Bit}\)。则用熵编码表示的平均比特率为:
\[ 1 \times \frac{1}{2} + 2 \times \frac{1}{4} + 3 \times \frac{1}{8} + 4 \times \frac{1}{8} = 1.875 \, \text{Bit} \]
压缩比 \(r\) 为 \(2:1.875\).
当然,以上方法也不是最佳的。它仅考虑单数编码。诸如 Huffman 编码的方法更为高级。
数据建模
信号基本上都具有强相关性,它们的内部结构能过通过数据模型来表达。以下图为例:
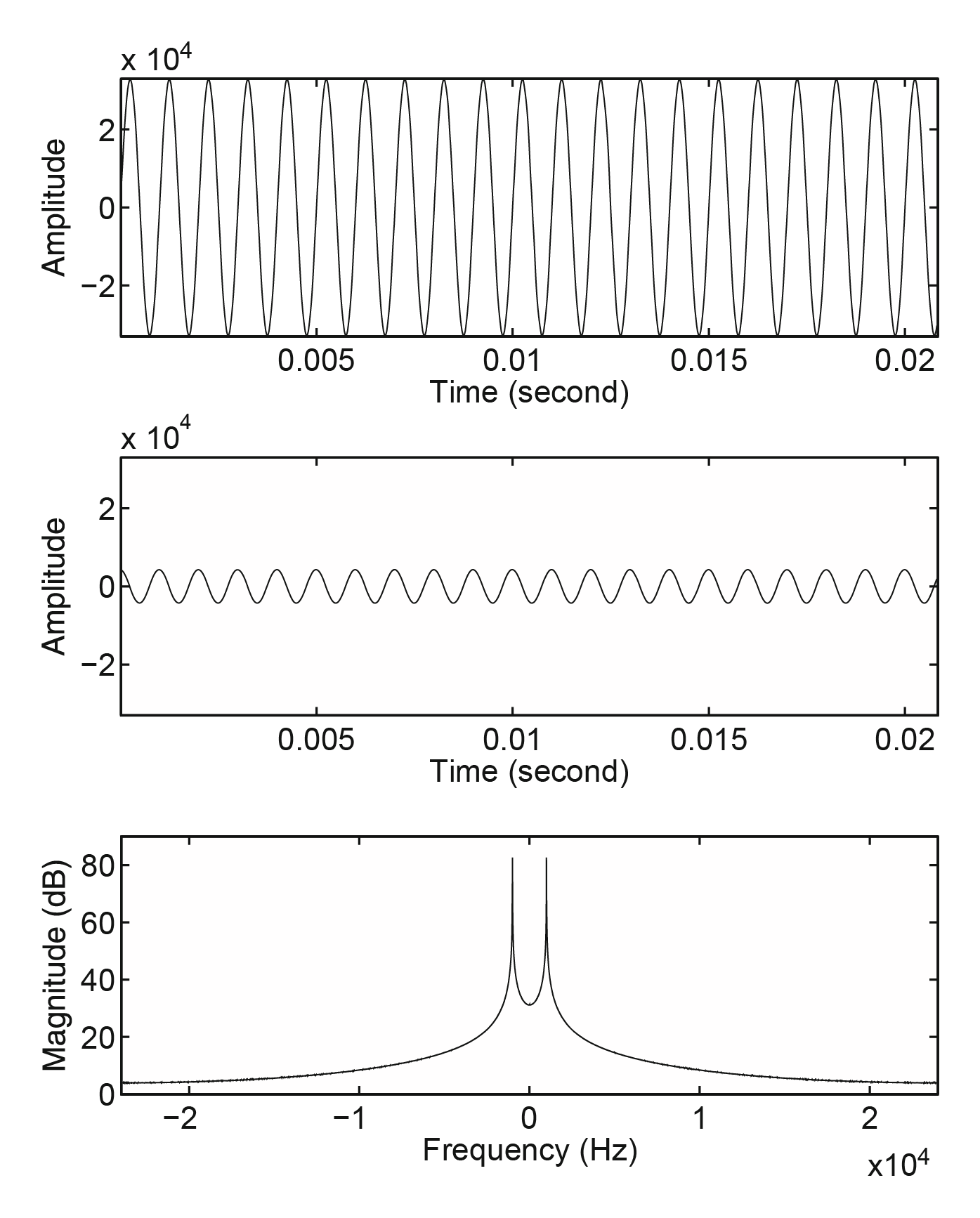
对于音频,可以通过线性预测(Linear Prediciton)移除相关性。\(x(n)\) 为第 \(n\) 个正弦信号的采样,\(\hat{x}(n)\) 是预测值。最简单的方式是将前一个采样,作为当前采样的预测:
\[ \hat{x}(n) = x(n-1) \]
这确实是一种预测,但不是一个优雅的实现。所以,这是它的「预测误差」,或曰「残差」(Prediction Error, aka Residual):
\[ e(n)=x(n)-\hat{x}(n) \]
如上图中间所示,如果我们使用处理后的信号,而非原始信号。解码器得到了一个相较而言非常小的数,这一过程显著降低了动态范围。准确而言,动态范围是 \([-4278, 4278]\) 可以用 \(14 \, \text{Bit}\) PCM 表示。压缩率 \(r\) 为 \(16:14\).
另一个去相关性的做法是正交变换(Orthogonal Transforms)。如上图下方所示,该图描绘了对数幅度的离散傅里叶变换(DFT,Discrete Fourier Transform)。不在时域中处理周期性出现的,正弦信号的大样本值;而在频域中处理少量的大 DFT 系数,其余的都接近于零。于是,可以根据 DFT 系数各自的大小,动态分配比特。此举压缩效果显著。
DFT 在实践中很少使用,因为 DFT 将实数域变换到复数域。对于一个由 \(N\) 个实数输入样本组成的块,DFT 产生由 \(N\) 个复数系数组成的块。它由 \(N\) 个实数和 \(N\) 个虚数系数组成。离散余弦变换(DCT,Discrete Cosine Transforms),是实数到实数的变换。DCT 用于替代 DFT。对于 \(N\),可以称其为块大小(block size)或块长度(block length)。
当块被独立编码时,块边界会出现块效应,即不连续现象。在音频中,会出现咔嚓声;在图像中,则会出现正方形小块。
可以看到,在 JPEG Q=10 压缩后,有严重的块效应:

为了克服块效应,可以使用重叠变换(overlapped transform),这是子带滤波器(subband filter)的一种。
然而,重叠变换消耗更多的资源。为了减轻消耗,通常在实践中使用 CMFB(余弦调制滤波器组,cosine modulated filter banks) 和 MDCT(修改的DCT,modified discrete cosine transform).
知觉模型
虽然数据模型可以在一定程度上提高压缩率,然而其功能有限。知觉模型就这样出现了。
音频
在音频下,可以使用心理声学模型,安全地去除知觉不相关信息。但人耳感觉不到失真。具体而言,人耳具有以下限制:
- 高频限制(High Frequency Limit),人耳理论可听范围为 \(20 \, \text{Hz}\) 到 \(20\,\text{kHz}\)。然而,随着年龄增长,很多成年人已然听不出 \(16 \, \text{kHz}\) 以上的声音了。所以,很多压缩会直接裁切掉 \(20 \, \text{kHz}\) 以上的高频。
- 绝对听阈(ATH,Absolute Threshold of Hearing),对不同频率,人耳的听阈都有所不同。ISO 226:2003 规定了一条听阈曲线。

Wikimedia 作者 Lindosland 已进入公有领域
{kind=link}
- 时间遮蔽(Temporal Masking)。
- 频谱遮蔽(Spectral Masking),例如,声音在 \(2\, \text{kHz}\) 上响度很高,那么 \(2.1 \, \text{kHz}\) 处的低响度声音,往往就会被掩盖。
联合通道编码
该技术如字面意思一样,仅适用于音频。在低码率下,该技术使用广泛。
因为音频的声道往往是协调且同步的,相关性非常强。虽然现有的方法仍然很原始。仅仅使用和差分编码(sum/difference coding)和联合强度编码(joint intensity coding)。
例如在 HE-AAC v2 中使用的参量立体声(PS,Parametric Stereo),就运用了该技术。
比特率分配机制
需要一种优化的比特分配机制,使得质量最优。
常用的分配机制有以下几种:
- CQP(Constant QP) CQP 是容易实现的一种策略,QP 即质量参数,也就是量化步长。它既不面向码率,又不面向质量。一般很少使用。
- CBR(Constant Bit Rate) CBR,即恒定码率。也是一种相当简单的编码策略。如字面意思,码率是恒定的,不考虑内容。即使是一段什么声音都没有的音频,或全是黑色的视频,如果给了高参数,那么文件也会非常之大。
- ABR(Average Bit Rate) ABR,即恒定平均码率。可以理解为 CBR 和 VBR 的折中方案。根据场景动态分配的同时,又不超过设定的区间。
- VBR(Variable Bit
Rate)
VBR,即可变码率。它根据场景动态分配,但无法指定码率范围。
- 2PASS VBR 的另一种编码模式,即对同一媒体编码两次,第一次区分复杂和简单场景,第二次视频平均码率不变。效果通常比 ABR 更好。
- CRF(Constant Rate Factor) CRF,即恒定码率系数。将视觉输出作为目标。需要输入的是预期质量。是面向质量的策略。
一般,在音频中只使用 CBR、ABR、VBR。而视频几乎都有使用。
本次主要讲了音频和一些通用的压缩方法。下一篇文章将会详细描述视频相关的。
主要参考
- You Y. Audio Coding: Theory and Applications[M]. Springer Science & Business Media, 2010. ISBN 9781441917539