
上篇文章我们讲解了几款经典垃圾收集器,本文将介绍 Shenandoah 低延迟垃圾收集器。
GC 不可能是完美的,可以通过有三个评判指标:内存占用(Footprint)、吞吐量(Throughput)、延迟(Latency)。它们三者构成了「不可能三角」,一款优秀的收集器可以达成其中的两项。
其中,延迟这一项越来越重要了。我们可以容忍多用一点点硬件,靠堆积内存和 CPU 提高吞吐,对冲内存占用。然而延迟却会随着内存增长而增加,因为回收耗时显然是会堆大小成正相关的。因此新 GC 往往会看中延迟。
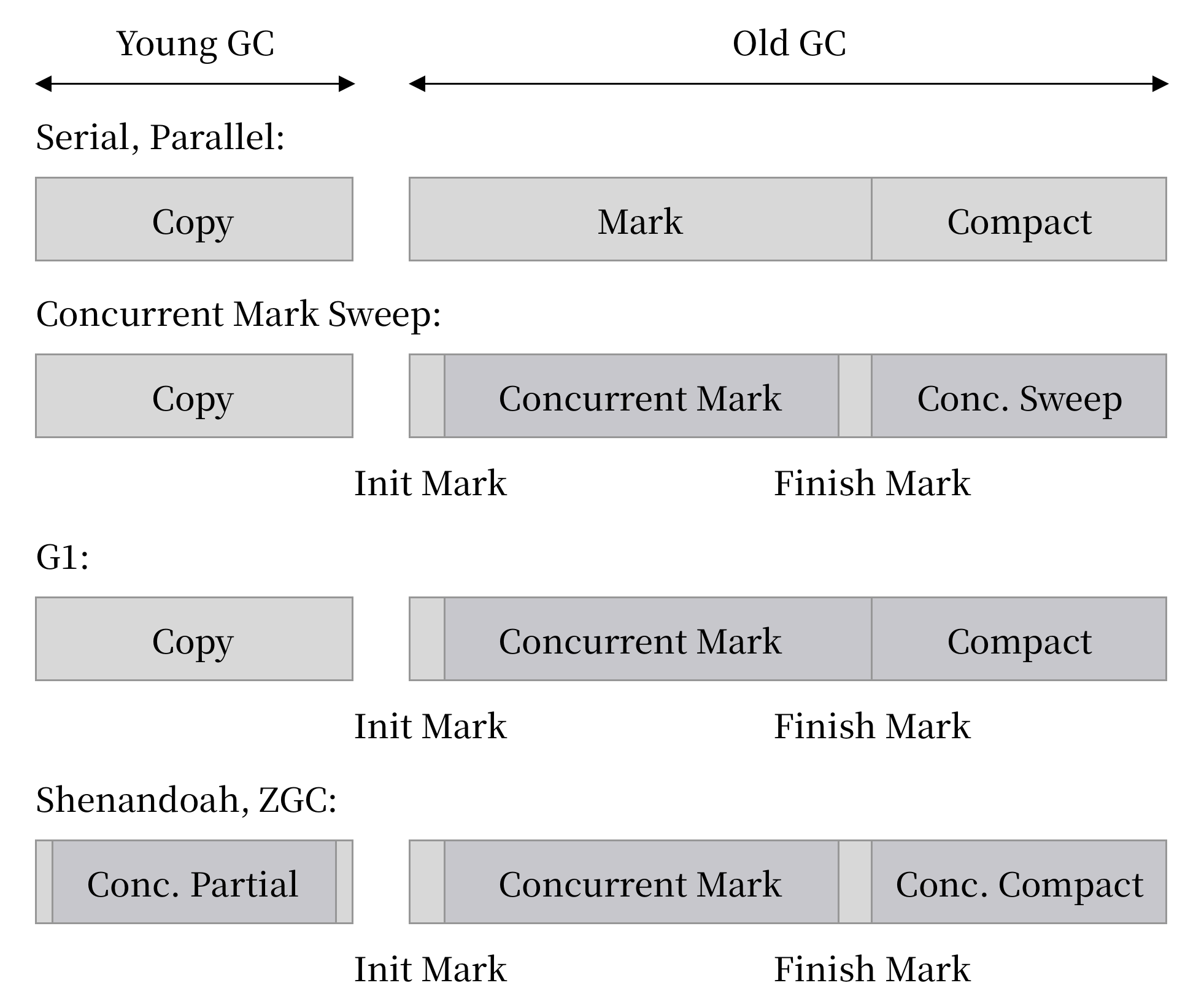
可以注意到,Shennandoah 和 ZGC 除了部分不太耗时的标记阶段,几乎都是并发的。
Shenandoah GC
值得一提,Shenandoah 是为数不多的,Oracle JDK 中没有,而 OpenJDK 中存在的 GC。开源版胜于商业版,怎么想都是罕见的情况。
Shenandoah 相比 G1,除了一致的使用 Region 堆布局、Humongous Region、根据 Decaying Average 判断价值之外,还存在一些不同之处:
支持并发整理,G1 的回收阶段虽然是多线程的,但是需要暂停用户线程
不使用分代收集,换而言之,没有专门的新生代 Region 或老年代 Region 存在。
不再使用记忆集,摒弃了耗费大量内存和 CPU 的数据结构。改用名为「连接矩阵」(Connection Matrix)的全局数据结构记录跨 Region 引用关系,这种数据结构类似一张二维数组,若 Region N 中有 Region M 的引用,则在
[N, M]处打上标记。
GC 过程
Shenandoah GC 的工作过程可以大致分为九个阶段:
- 初始标记(Initial Marking):类似 G1,标记 GC Roots 的直接引用,STW,但停顿时间和堆大小是无关的,只和 GC Roots 的数量有关。
- 并发标记(Concurrent Marking):遍历对象图,标记出可达对象,和用户线程并发。用时取决于对象数量和对象结构复杂度。
- 最终标记(Final Marking):SATB 扫描,并将回收价值高的 Region 构成回收集。会短暂停止。
- 并发清理(Concurrent Cleanup):用于清理,一整个区域都无存活对象的 Region(Immediate Garbage Regions)。
- 并发回收(Concurrent Evacuation):这里是区别于其他 GC 的核心差异。本阶段,Shenandoah 会将回收集的存活对象复制到未使用的 Region 之中。若复制时冻结用户线程,那是相当简单的;但如果两者并发运行,就变得复杂起来了。在移动对象的同时,用户线程可能仍在不停读写对象。移动对象时,需要更新所有内存中对旧地址的引用。而 Shenandoah 使用读屏障和 Brooks Pointer 的转发指针解决了这一问题(后文会详细介绍)。本阶段用时取决于回收集大小。
- 初始引用更新(Concurrent Update Reference):复制完毕后,需要更新旧地址到新地址,即引用更新。然而本阶段没有具体操作,只是建立了线程集合点,确保回收线程分配对应的对象。会产生非常短暂的停顿。
- 并发引用更新(Concurrent Update Reference):与用户线程并发。耗时取决于引用多少。与并发标记不同,本阶段无需依靠对象图,是按照内存物理地址顺序搜索,过滤出引用类型并更新。
- 最终引用更新(Final Update Reference):解决了堆的引用,还需要解决 GC Roots 中的。是一次 GC 过程中的最后一次停顿,耗时与 GC Roots 数量有关。
- 并发清理(Concurrent Cleanup):类似第 4 步。重新清除 GC 过程中产生的 Immediate Garbage Regions。
其中最重要的是 3 个并发阶段:并发清理、并发回收、并发引用更新。
下图为官方 Wiki 配图:

Brooks Pointer
接下来我们介绍 Brooks Pointer。Brooks 在 1984 年提出了使用转发指针(Forwarding Pointer, Indirection Pointer)来实现对象移动和用户程序并发的一种方法,因此得名 Brooks Pointer。
传统的方法是,在对象原有内存上设置保护陷阱(Memory Proteciton Trap),一旦访问到,就会自陷中断,进入预设好的异常处理器中,再把访问转发到复制后的新对象上。这种方法虽然可行,但性能堪忧,需要系统反复在用户态和核心态之间切换。
Brooks Pointer 在原有对象布局前,新增一个指向自己的引用。这类似之前提到过的句柄池转发。但间接对象访问的缺点都相同且明显——每次访问都会带来一次额外的转向开销。
虽然此开销可以精简到只有一行汇编指令的程度。但毕竟访问对象是十分常用、频繁的操作,仍然是一笔不可忽视的成本,只是比保护陷阱好了很多。
Brooks Pointer 还存在多线程资源竞争问题。如果是并发读取,不会出现什么问题。然而如果是并发写入,将会是非常疯狂的。不妨设想以下几件事同时发生。
收集器线程复制了新的对象副本
用户线程更新对象的某几个字段
收集器线程更新转发指针
若 2 在 1 和 3 之间执行,结果将是用户线程的操作变更在旧对象上。所以在这里,需要采取同步措施。让用户线程和收集器线程之一成功,另一个等待。而 Shenandoah 实际上使用 CAS 操作保证并发时对象访问的正确性。
保证并发
用户线程的「对象访问」说得轻巧,然而很多操作,诸如读取、写入、比较、计算散列值、加锁等。无不属于对象访问,只要一个程序在运行,对象访问就非常频繁且一刻不停。Shenandoah 在刚发布时(JDK 12),为了要覆盖全部对象的访问操作,不得不同时设置读屏障和写屏障。
试想以下代码:
public class User {
public long phone;
public int age;
}
public class Holder {
public User user;
}
class Test {
void handle(Holder holder) {
var user = holder.user;
for (;;) {
var zip = user.zip;
System.out.println(zip);
user.age = 100;
}
}
}在 JDK 12 的 Shenandoah 中,实际执行的语句类似这样:
void handle(Holder holder) {
var user = RB(holder).user;
for (;;) {
var zip = RB(user).zip;
System.out.println(zip);
WB(user).age = 100;
}
}其中,RB() 表示读屏障,WB() 表示写屏障。在
for 循环中读一次 zip
都需要读屏障,带来的影响是非常大的。假设这段代码被频繁运行——甚至放在另一个更大的循环中执行,非常影响印象。而读是非常频繁的操作,所以
Shenandoah 这一点为人诟病,而开发者也知道这个问题。
所以,在 JDK 13 中,读、写屏障被移除,取而代之的是加载引用屏障(Load Reference Barrier)。也就是说,只有对于引用类型会有屏障检查,而对原生类型如 int,long 等没有。执行时类似这样:
void handle(Holder holder) {
var user = LRB(holder).user;
for (;;) {
var zip = user.zip;
System.out.println(zip);
user.age = 100;
}
}在 JDK 14 中,还引入了自固定屏障(Self-fixing Barrier)。
JDK 13 中的加载引用屏障用伪代码表示,类似这样:
T load_reference_barrier(T* addr) {
T obj = *addr;
// Fast-path: accesses thread-local flag
if (!is_gc_active()) return obj;
// Mid-path 1: accesses small bitmap (byte per region, handful of KBs?)
if (!is_in_collection_set(obj)) return obj;
// Mid-path 2: accesses fwdptrs in object (entire heap?)
T fwd = resolve_forwardee(obj);
if (obj != fwd) return fwd;
// Slow-path: call to runtime, once per location with non-forwarded object
return load_reference_barrier_slowpath(obj);
}每一次对象都会进入该方法。而若未处于 GC 状态,则 fast return。在这之后,如果是回收集引用,就会深入解析该对象。想象一段代码在 for 循环里,mid-path 2 对性能的损失是很大的,它的范围比较广。而 Self-fixing Barrier 就是解决问题的办法。基本思路是当我们解析出了对象,并发现了转发的副本的同时,更新位置。下次就会在 Mid-path 1 直接退出。
T load_reference_barrier(T* addr) {
T obj = *addr;
// Fast-path: accesses thread-local flag
if (!is_gc_active()) return obj;
// Mid-path 1: accesses small bitmap (byte per region, handful of KBs?)
if (!is_in_collection_set(obj)) return obj;
// Mid-path 2: accesses fwdptrs in objects (entire heap?)
T fwd = resolve_forwardee(obj);
if (obj != fwd) {
// Can do the update here
CAS(addr, fwd, obj);
return fwd;
}
// Slow-path: call to runtime, once per location with non-forwarded object
fwd = load_reference_barrier_slowpath(obj);
// Can do the update here
CAS(addr, fwd, obj);
return fwd;
}同时,上述方法可以简化,我们不必再使用 mid-path 2
来检查,而是对每次通过 mid-path 的 LFB 都执行
load_reference_barrier_slowpath。
T load_reference_barrier(T* addr) {
T obj = *addr;
// Fast-path: accesses thread-local flag
if (!is_gc_active()) return obj;
// Mid-path 1: accesses small bitmap (byte per region, handful of KBs?)
if (!is_in_collection_set(obj)) return obj;
// Slow-path: call to runtime, once per non-updated location
return load_reference_barrier_slowpath(obj, addr); // Update is actually here
}虽然在代码上看起来,直接 call to runtime 会耗费时间。但 mid-path 2 往往比 call to runtime 更加耗时。
消除转发指针
可能你会觉得作为 Shenandoah 的基本要求,Brooks 转发指针是必须的。然而实际上并非如此。
Hotspot VM 中常见的对象布局为:
0 --- mark-word
8 --- class-word
16 --- field 1
24 --- field 2
32 --- field 3每个部分都是一个堆字(Heap Word)。根据系统架构不同而不同,如常见的 32 和 64 位。
mark-word 就是对象 header。之前提到过,它的用途不被特定,可以用于锁、GC 年龄等。
第二个字为类指针保留,这是一个指向 HotSpot VM 类定义的指针。
Array 还会有额外的字用于储存数组长度。后面才是真正的内容。
当使用 Shenandoah GC 时,还会额外增加
-8 --- forward pointer然而这会带来额外的内存消耗以及转发调用,尽管如之前所说,转发操作只需要一行汇编。
在 JDK 13 加载引用屏障基础上,消除转发指针变得容易。在并发回收时,拷贝对象的原本(from-space)也不被允许任何访问。这意味着原本可以被随意修改,比如用于储存转发指针,而不是保留额外的字。现在的结构将类似于:
0 --- [mark-word] or [forward pointer]
8 --- class-word
16 --- field 1
24 --- field 2
32 --- field 3在 load reference barrier 方法被调用时,可以执行对应的解码操作:
oop decode_forwarding(oop obj) {
mark m = obj->load_mark();
if ((m & 0b11) == 0b11) {
return (oop) (m & ~0b11);
} else {
return obj;
}
}这解决了内存问题,并带来了额外收获:
- 增加吞吐,在 GC 触发前分配更多对象
- 对象更紧密,可以更好的利用 CPU 缓存
- 内部实现变得更简单了,维护起来更容易
Stack Watermark
栈水位(Stack Watermark)用于减缓为数不多的暂停环节的影响,即初始标记和最终标记。
该技术于 JDK 17 中实现,用于 ZGC 和 Shanendoah GC。
在 GC 开始时需要扫描堆栈用于后续处理。较小的程序堆栈一般不深。然而,大项目时常到达 300 多的堆栈是不足为奇的。此时就该 Stack Watermark 了。
核心思路是,可以边扫描边执行。原本 GC 时,会将所有阵栈都锁定,再统一扫描。但 GC 不可能一瞬扫描完,需要时间运行。通过设置 Watermark,可以实现 GC 线程和用户线程的协调。Watermark 区分哪些部分可以安全执行,哪些部分不能。
通过该优化,Shanendoah GC 实现了惊人的亚毫秒级 GC 暂停。
| Version | Init mark | Final mark |
|---|---|---|
| 11 | \(421\,\mu s\) | \(1294\,\mu s\) |
| 16 | \(321\,\mu s\) | \(704\,\mu s\) |
| 17 | \(63\,\mu s\) | \(328\,\mu s\) |
本文内容就先到这里,下节继续讲解 ZGC。