
指针(Pointer)是一个包含内存地址变量的通用概念。这个地址引用,或谓「指向」一些其他的数据。Rust
中最常见的指针是引用(Reference)。引用以
&
符号标识它们借用所指的值。引用很简单,也没有特殊功能,所以用得最多。
另一方面,智能指针(smart pointers)是一类特殊的数据结构,表现类似指针,但拥有额外的元数据和功能。智能指针这个概念起源于 C++ 并在其他语言中流行,Rust 也不例外。
值得注意的是,在 Rust 中,普通指针和智能指针最显著的区别是:引用只借用数据;智能指针拥有它们所指的数据。
实际上,String Vec<T>
这种数据类型,在广义上也可以称之为智能指针(虽然没人这么叫)。的确拥有数据所有权,并有额外的元数据和功能。
智能指针通常使用结构体实现,并实现 Deref 和
Drop trait。Deref
允许智能指针结构体表现得像引用一样,这样就可以编写既用于引用、又用于智能指针的代码。Drop
trait 我们之前已经涉及到,允许结构体在离开作用域时自动清除。
Box<T>
Box<T>
是最简单直接的智能指针,它允许你将一个值放在堆上,而不是栈上。留在栈上的指向堆的指针。常用于以下场景:
- 有一个编译时大小未知的类型
VecHashMapString肯定都用到了Box<T>
- 数据很大,我们希望数据不被拷贝,仅转移所有权
- 当拥有一个值,只关心它的类型是否实现了特定的 trait 而非具体类型时
- 在之前我们介绍过 trait 的缺陷,可以利用
Box<T>+dyn关键字可以实现 trait 对象解决这个问题,不过本篇暂时还不会介绍
- 在之前我们介绍过 trait 的缺陷,可以利用
基本语法
fn main() {
let b = Box::new(5);
println!("b = {b}")
}
// Output:
// 5很简单,定义后使用即可。当然,b 也遵守所有权规则。在
main 函数结束时,它将被释放,作用于 box
本身(在栈上)和它所指的数据(在堆上)。
但这样将一个单独的值存放在堆上意义不大。下面我们将介绍一个实际的用例。
创建递归类型
Rust
需要在编译时知道类型占用的空间。一种无法在编译时知道大小的类型是递归类型(recursive
type),其值的一部分,可以是相同类型的另一个值。这种值的嵌套可以无限进行。所以
Rust 并不知道递归类型所需的类型。但只要使用
Box<T>,该值在栈上的大小就是固定的,自然就可以创建递归类型了。
让我们定义一个 cons list:
enum List {
Cons(i32, List),
Nil,
}为了示例尽可能简单,这里就直接用具体类型
i32了。当然也可以使用泛型,来创建可以存放任何类型的 cons list。
我们期望这样使用它:
use crate::List::{Cons, Nil};
fn main() {
let list = Cons(1, Cons(2, Cons(3, Nil)));
}然而遗憾的是,上述代码会编译错误。
error[E0072]: recursive type `List` has infinite size
|
3 | enum List {
| ^^^^^^^^^ recursive type has infinite size
4 | Cons(i32, List),
| ---- recursive without indirection
|
help: insert some indirection (e.g., a `Box`, `Rc`, or `&`) to make `List` representable
|
4 | Cons(i32, Box<List>),
| ++++ +正如错误信息所描述的,这个类型有「无限的大小」。栈上的空间必须是已知的。
所以,我们可以间接地存储一个值,如使用
Box(建议中还给出了 Rc ,这在后面介绍)。
这样就好了:
use crate::List::{Cons, Nil};
enum List {
Cons(i32, Box<List>),
Nil,
}
fn main() {
let list = Cons(1, Box::new(Cons(2, Box::new(Cons(3, Box::new(Nil))))));
}Deref trait
Deref trait
允许我们重载解引用操作符(dereference
operator)*。所以实现 Deref
的智能指针可以当作常规引用看待。可以编写操作引用的代码,并用于智能指针。
通过解引用追踪指针的值
fn main() {
let x = 5;
let y = &x;
assert_eq!(5, x);
assert_eq!(5, *y);
}很简单的示例,x 存放了一个 i32
值。y 绑定 x 的引用。可以断言
x == 5。然而如果希望对 y
的值做出断言,我们则需要用 *y
追踪引用所指的值(解引用)。一旦解引用了 y,就可以访问
y 所指的 i32 类型值,并和 5
比较了
像引用一样使用
Box<T>
通过 Deref trait,使用 Box<T>
的方式惊人的相似:
fn main() {
let x = 5;
let y = Box::new(x);
assert_eq!(5, x);
assert_eq!(5, *y);
}这正是 Deref 特性的方便之处,减少了很多重复工作。
自定义智能指针
这里的
MyBox<T>用作示例,实际上和普通指针的功能一样,都是在栈上分配空间。
不妨实现一个 MyBox<T> 智能指针:
struct MyBox<T>(T);
impl<T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}现在使用解引用操作符会报错:
fn main() {
let my_box = MyBox::new(13);
assert_eq!(*my_box, 13);
}error[E0614]: type `MyBox<{integer}>` cannot be dereferenced
|
11 | assert_eq!(*my_box, 13);
| ^^^^^^^我们可以实现 Deref:
use std::ops::Deref;
impl<T> Deref for MyBox<T> {
type Target = T;
fn deref(&self) -> &Self::Target {
&self.0
}
}其中 type Target = T;
的语法尚未遇到,不过这不影响理解。这留到后面去介绍。只需要知道
&Self::Target 和直接使用 T 类似即可。
这样,之前的代码就可以编译通过了。
实际上,Rust 在幕后将 *my_box 替换为了
*(my_box.deref())。很方便的语法糖。
请注意,*
操作符只会解一次引用,不会无限递归替换。也就是说多个引用或智能指针需要多次解引用。
Deref 隐式强转
Deref 强制转换(deref
coercions)是在函数或方法传参上的一种便利。用于实现了 Deref
trait 的类型。将一个类型的引用,转为另一个类型的引用。例如
&String 到 &str,因为
String 实现了 Deref trait,因此可以返回
&str。
这减少了反复显式使用 & *
可能,也使得我们可以编写更通用的代码。
参看以下示例,这里使用了之前定义的 MyBox<T>:
fn hello(name: &str) {
println!("Hello, {}!", name);
}
fn main() {
let m = MyBox::new(String::from("Rust"));
hello(&m);
}这里调用了两次不同类型的 deref。先是将
&MyBox<String> 类型变为
&String,之后又将其变为 &str。
如果 Rust 没有该特性,可能要这样写:
fn main() {
let m = MyBox::new(String::from("Rust"));
hello(&(*m)[..]);
}(*m) 将 MyBox<String> 解引用为
String,接着 & 和 [..]
获取了整个 String 字符串的 slice 来匹配 hello
的函数签名 &str。一堆符号混在一起难以阅读和理解。
所以有了 Deref
我们可以更轻松地使用智能指针,且没有运行时损耗(解析发生在编译时)。
和可变性交互
类似于 Deref 可以重载不可变引用的 *
运算符,Rust 也提供了 DerefMut 用于重载可变引用的
*。
Rust 在以下情况强制转换:
T: Deref<Target=U>时,&T到&UT: DerefMut<Target=U>时,&mut T到&mut UT: Deref<Target=U>时,&mut T到&U
头两个情况没什么解释的。第三种情况很微妙:
Rust 会将可变引用转为不可变的。但是反之是不可能的。根据借用规则,如果有一个可变引用,其必须是这些数据的唯一引用。将可变强转为不变不会打破借用规则;但不变转为可变,需要假定该不变引用是该数据唯一的引用,而借用规则无法保证这一点。所以 Rust 不允许将不可变引用转换为可变引用。
Drop trait
Drop trait
允许值离开作用域时执行一些代码,可以为任何类型指定 Drop
的实现。可以将该特性用于释放文件或网络连接。我们在此讨论该
trait,是因为它总是用于实现智能指针。例如,当 Box<T>
被丢弃时会释放 box 指向的堆空间。
在其他语言中,可能需要在使用智能指针实例后,手动调用清理内存或资源的代码,如果忘记清理,运行代码的系统很有可能因为负担过重崩溃。但 Rust 使用该方式能够自动在实例结束时清理,并且没有资源泄漏。
不妨查看以下代码:
struct CustomSmartPointer {
data: String,
}
impl Drop for CustomSmartPointer {
fn drop(&mut self) {
println!("Dropping CustomSmartPointer with data `{}`!", self.data);
}
}
fn main() {
let c = CustomSmartPointer {
data: String::from("my stuff"),
};
let d = CustomSmartPointer {
data: String::from("other stuff"),
};
println!("CustomSmartPointers created.");
}这里我们用 println()
替代实际清理资源的逻辑。在变量离开作用域时,会自动调用
drop(),所以输出如下:
CustomSmartPointers created.
Dropping CustomSmartPointer with data `other stuff`!
Dropping CustomSmartPointer with data `my stuff`!提前调用 drop
Rust 不允许我们手动调用 drop()
方法,但我们可能切实需要提早清理某个值。典型例子是在使用智能指针管理锁时,我们会希望提前调用
drop 释放锁使得其他代码可以获取锁。所以可以使用
std::mem::drop 提早丢弃值。
以下代码会报错:
fn main() {
let c = CustomSmartPointer {
data: String::from("some data"),
};
println!("CustomSmartPointer created.");
c.drop();
println!("CustomSmartPointer dropped before the end of main.");
}error[E0040]: explicit use of destructor method
|
16 | c.drop();
| --^^^^--
| | |
| | explicit destructor calls not allowed
| help: consider using `drop` function: `drop(c)`错误信息表明,我们提前使用了析构函数(destructor),这是和构造函数(constructor)相反的概念。Rust
中的 drop 就是一种析构函数。
报错是因为这会引起 double free
错误,程序会尝试清理两次同样的值。
但可以用
std::mem::drop,因为它的语义是「提早清理」,也就是说在作用域结束时,不会再调用一次。
该函数位于预导入中,所以可以不用导包:
fn main() {
let c = CustomSmartPointer {
data: String::from("some data"),
};
println!("CustomSmartPointer created.");
drop(c);
println!("CustomSmartPointer dropped before the end of main.");
}现在的打印信息如下:
CustomSmartPointer created.
Dropping CustomSmartPointer with data `some data`!
CustomSmartPointer dropped before the end of main.Rc<T> 引用记数
有时候为了实现多所有者,我们需要使用引用记数(reference
counting),在 Rust 中对应的类型是 Rc<T>。
这意味会记录用一个值记录引用的数量,来判断是否仍在被使用。如果某个值有零个引用,就代表没有任何有效引用,可以被清理。
当我们希望一个值供程序中多个部分使用时,且不知道那一部分会先结束,我们就可以用
Rc<T> 实现。
注意:Rc<T> 只能用于单线程场景。
假设我们要实现以下数据结构。
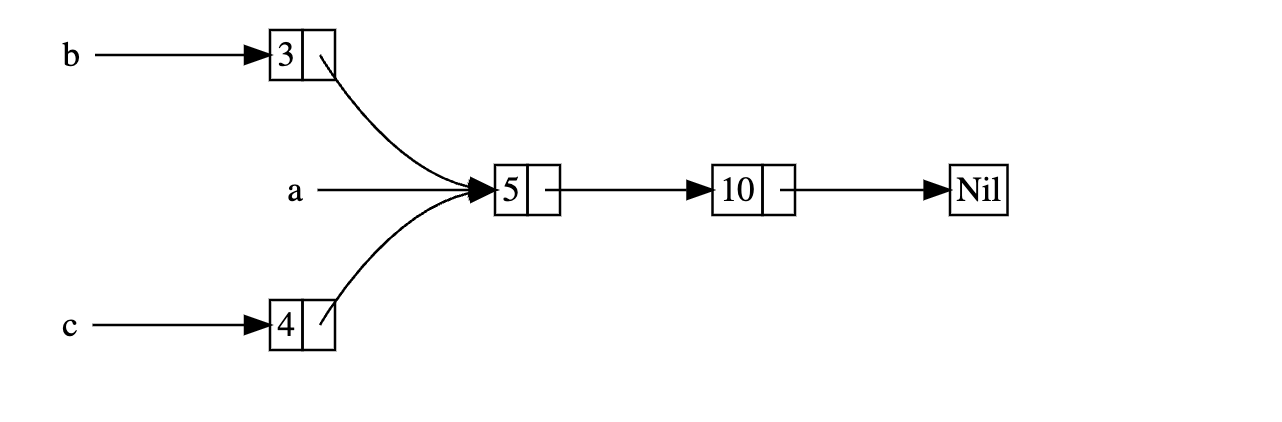
用 Box<T> 不能实现该数据结构。
enum List {
Cons(i32, Box<List>),
Nil,
}
use crate::List::{Cons, Nil};
fn main() {
let a = Cons(5, Box::new(Cons(10, Box::new(Nil))));
let b = Cons(3, Box::new(a));
let c = Cons(4, Box::new(a));
}error[E0382]: use of moved value: `a`
--> src/bin/playground.rs:11:28
|
9 | let a = Cons(5, Box::new(Cons(10, Box::new(Nil))));
| - move occurs because `a` has type `List`, which does not implement the `Copy` trait
10 | let b = Cons(3, Box::new(a));
| - value moved here
11 | let c = Cons(4, Box::new(a));
| ^ value used here after moveCons 成员拥有其储存的数据,所以当创建列表 b
时,a 已经移动去了 b,这样 b
就有了 a。接着当 c 使用 a
时,就会报错,因为 a 的所有权已经被移动。
可以改变 Cons
的定义来存放引用,然后指定生命周期参数。但这不是普遍的情况。
相反,我们可以修改 Box<T> 为
Rc<T>。如下所示:
enum List {
Cons(i32, Rc<List>),
Nil,
}
use crate::List::{Cons, Nil};
use std::rc::Rc;
fn main() {
let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil))))); // rc + 1
let b = Cons(3, Rc::clone(&a)); // rc + 1
let c = Cons(4, Rc::clone(&a)); // rc + 1
}使用引用计数,将允许多个值共享所有权。
Rc::clone()
不会获取所有权,但也不会深拷贝整个列表,只是增加引用记数。
下面的例子可以更清晰地看出引用记数值的变化:
fn main() {
let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil)))));
println!("count after creating a = {}", Rc::strong_count(&a));
let b = Cons(3, Rc::clone(&a));
println!("count after creating b = {}", Rc::strong_count(&a));
{
let c = Cons(4, Rc::clone(&a));
println!("count after creating c = {}", Rc::strong_count(&a));
}
println!("count after c goes out of scope = {}", Rc::strong_count(&a));
}count after creating a = 1
count after creating b = 2
count after creating c = 3
count after c goes out of scope = 2在程序中每个引用记数变化的点,会打印出引用记数,可以通过
Rc::strong_count() 获取,叫 strong_count 而非
count,是因为 Rc<T> 也有
weak_count。
我们能够看到每次 clone,引用记数值都会增加 1。当
c 离开作用域时,记数减 1。不必像调用 Rc::clone
一样来手动操作记数减少,因为实现了 Drop
trait,所以会在离开作用域时自动减少。
Rc<T> 只允许在程序的多个部分之间只读地共享数据。若
Rc<T>
允许多个可变引用,则会违反之前讨论过的借用规则:相同位置的多个可变借用可能造成数据竞争和不一致。
RefCell<T>
和内部可变性
内部可变性(Interior mutability)是 Rust
中的一个设计模式。允许在不可变引用存在时,也可以改变数据。为了改变数据,该模式会使用
unsafe 代码模糊 Rust 通常的可变性和借用规则。将
unsafe 代码封装进安全的 API 中,这就是
RefCell<T> 所做的。
不同于 Rc<T>,RefCell<T>
代表其数据的唯一所有权。那么为何 RefCell<T> 不同于
Box<T> 呢?
答案很简单,对于引用和
Box<T>,借用规则的不可变性作用于编译时。但对
RefCell<T>
是作用于运行时。对于引用,会引发编译时错误;而对于
RefCell<T> 会在运行时 panic 并退出。
编译时检查借用的优势在于,这些错误会在编译时被捕获,并且对性能没有影响。所以这通常是最佳选择,也是 Rust 的默认行为。
相反在运行时检查,会带来动态性的好处,有些场景在运行时是内存安全的,但在编译检查中却不允许。静态分析,如 Rust 编译器,是天生保守的。代码的一些属性不可能通过分析代码发现,其中最著名的就是停机问题。
RefCell<T>
用于你确信代码遵循借用规则,但编译器却不能理解和确定的时候。
类似 Rc<T> RefCell<T>
也只能用于单线程场景。
在不可变值内部改变值就是内部可变性模式。不妨查看一个实际的例子。
Mock 对象
测试替身(test double)是一个通用编程概念,它代表一个在测试中替代某个类型的类型。mock 对象是特定类型的测试替身,它们记录测试过程中发生了什么以便可以断言操作是正确的。
查看以下代码,我们要记录一个值与最大值的差距,并根据该差距发送消息。例如,可以用于记录用户所允许的 API 调用限额。
pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger,
{
pub fn new(messenger: &T, max: usize) -> LimitTracker<T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}如果我们想要测试并断言这些代码的逻辑,我们可以创建一个 Mock 对象。
#[cfg(test)]
mod tests {
use super::*;
struct MockMessenger {
sent_messages: Vec<String>,
}
impl MockMessenger {
fn new() -> MockMessenger {
MockMessenger {
sent_messages: vec![],
}
}
}
impl Messenger for MockMessenger {
fn send(&self, message: &str) {
self.sent_messages.push(String::from(message));
}
}
#[test]
fn it_sends_an_over_75_percent_warning_message() {
let mock_messenger = MockMessenger::new();
let mut limit_tracker = LimitTracker::new(&mock_messenger, 100);
limit_tracker.set_value(80);
assert_eq!(mock_messenger.sent_messages.len(), 1);
}
}不过以上代码无法通过编译。编译器抱怨 self.sent_messages
不可变,所以无法调用 push。
我们无法将 send 的签名改变为
&mut self,因为它们是公共 API 的一部分。所以我们可以用
RefCell 来储存 sent_messages:
#[cfg(test)]
mod tests {
use super::*;
use std::cell::RefCell;
struct MockMessenger {
sent_messages: RefCell<Vec<String>>,
}
impl MockMessenger {
fn new() -> MockMessenger {
MockMessenger {
sent_messages: RefCell::new(vec![]),
}
}
}
impl Messenger for MockMessenger {
fn send(&self, message: &str) {
self.sent_messages.borrow_mut().push(String::from(message));
}
}
#[test]
fn it_sends_an_over_75_percent_warning_message() {
let mock_messenger = MockMessenger::new();
let mut limit_tracker = LimitTracker::new(&mock_messenger, 100);
limit_tracker.set_value(80);
assert_eq!(mock_messenger.sent_messages.borrow().len(), 1);
}
}对于 RefCell<T> 来说,我们可以使用
borrow 或 borrow_mut 对应 &
和 &mut,分别返回 Ref<T> 和
RefMut<T>。这两个类型都实现了
Deref,所以可以当作常规引用对待。
RefCell<T> 内部记录了有多少个
Ref<T> 和 RefMut<T>
智能指针。每次调用
borrow,不可变借用记数加一,离开作用域时减一。就像是编译时的规则一样,RefCell<T>
允许多个不可变引用,或者一个可变引用。
如果违反规则,则会在运行时 panic。比如这样:
impl Messenger for MockMessenger {
fn send(&self, message: &str) {
let mut one_borrow = self.sent_messages.borrow_mut();
let mut two_borrow = self.sent_messages.borrow_mut();
one_borrow.push(String::from(message));
two_borrow.push(String::from(message));
}
}already borrowed: BorrowMutError
thread 'tests::it_sends_an_over_75_percent_warning_message' panicked at 'already borrowed: BorrowMutError', src/main.rs:62:47
// ....结合 Rc<T> 和
RefCell<T>
Rc<T> 允许多个不可变引用,而
RefCell<T>
允许内部可变性。如果将两者组合,我们就可以获得多个可变数据的所有者:
#[derive(Debug)]
enum List {
Cons(Rc<RefCell<i32>>, Rc<List>),
Nil,
}
use crate::List::{Cons, Nil};
use std::cell::RefCell;
use std::rc::Rc;
fn main() {
let value = Rc::new(RefCell::new(5));
let a = Rc::new(Cons(Rc::clone(&value), Rc::new(Nil)));
let b = Cons(Rc::new(RefCell::new(3)), Rc::clone(&a));
let c = Cons(Rc::new(RefCell::new(4)), Rc::clone(&a));
*value.borrow_mut() += 10;
println!("a after = {:?}", a);
println!("b after = {:?}", b);
println!("c after = {:?}", c);
}输出如下:
a after = Cons(RefCell { value: 15 }, Nil)
b after = Cons(RefCell { value: 3 }, Cons(RefCell { value: 15 }, Nil))
c after = Cons(RefCell { value: 4 }, Cons(RefCell { value: 15 }, Nil))循环引用和内存泄漏
Rust
的内存安全性保证难以意外地制造内存泄漏,但并非完全不可能。在编译时拒绝数据竞争不同,Rust
并不保证完全地避免内存泄漏,也就是说,Rust
认为内存泄漏是内存安全的。可以通过 Rc<T> 和
RefCell<T> 看出:创建循环引用的可能性存在。
制造循环引用
我们可以定义和之前类似的 cons list:
use crate::List::{Cons, Nil};
use std::cell::RefCell;
use std::rc::Rc;
#[derive(Debug)]
enum List {
Cons(i32, RefCell<Rc<List>>),
Nil,
}
impl List {
fn tail(&self) -> Option<&RefCell<Rc<List>>> {
match self {
Cons(_, item) => Some(item),
Nil => None,
}
}
}我们使用 RefCell<Rc<List>> 定义
Cons 的第二个元素,这意味着可以修改 Cons
所指向的 List,还有一个 tail
方法来方便我们在有 Cons 成员时访问其第二项。
以下代码会产生循环引用:
fn main() {
let a = Rc::new(Cons(5, RefCell::new(Rc::new(Nil))));
println!("a initial rc count = {}", Rc::strong_count(&a));
println!("a next item = {:?}", a.tail());
let b = Rc::new(Cons(10, RefCell::new(Rc::clone(&a))));
println!("a rc count after b creation = {}", Rc::strong_count(&a));
println!("b initial rc count = {}", Rc::strong_count(&b));
println!("b next item = {:?}", b.tail());
if let Some(link) = a.tail() {
*link.borrow_mut() = Rc::clone(&b);
}
println!("b rc count after changing a = {}", Rc::strong_count(&b));
println!("a rc count after changing a = {}", Rc::strong_count(&a));
// println!("a next item = {:?}", a.tail());
}输出:
a initial rc count = 1
a next item = Some(RefCell { value: Nil })
a rc count after b creation = 2
b initial rc count = 1
b next item = Some(RefCell { value: Cons(5, RefCell { value: Nil }) })
b rc count after changing a = 2
a rc count after changing a = 2b 有 a 的引用,而 a 也有
b 的引用。在作用域结束后,a 和 b
的记数值(2)减 1,仍然为 1。两个值互相维系,让值永远大于 1。
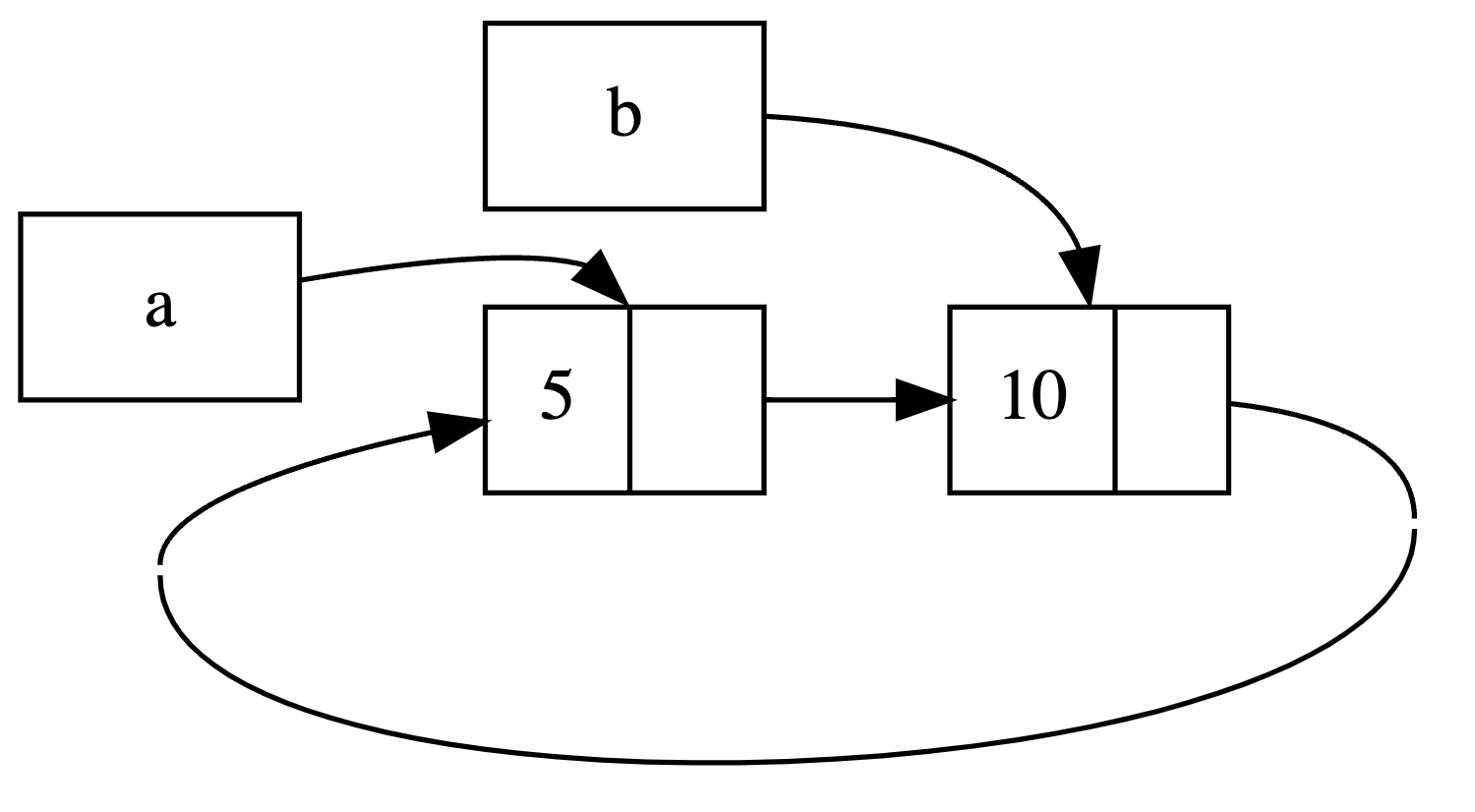
如果取消最后 println! 的注释并运行程序,Rust
会尝试打印出 a 指向 b 指向 a
这样的循环直到栈溢出。
本例中,循环引用的结果并不可怕。但如果在更为复杂的系统中出现了内存泄漏,可能会造成性能下降甚至崩溃。
创建循环引用并不容易,但并非不可能。再使用 Rc<T>
的 RefCell<T>
值或类似的嵌套结合了内部可变性和引用计数的类型,应注意避免循环引用。创建引用循环是一个程序上的逻辑
bug,应该使用测试、code review 或其他方式最小化。
另一个解决方案是重新组织数据结构,使得一些引用拥有所有权。但在本例中是不可能的,我们希望
Cons 成员拥有其列表。
使用 Weak<T>
我们知道 Rc::clone 会增加 Rc<T>
实例的 strong_count,并且 Rc<T> 只在
strong_count 为 0 时才会被清理。
我们还可以调用 Rc::downgrade 并传入
Rc<T>
实例的引用创建其值的弱引用(weak reference)。调用
Rc::downgrade 时会得到 Weak<T>
的智能指针。不同于将 Rc<T> 实例的
strong_count 加 1。调用 Rc::downgrade 会使得
weak_count 加 1。Rc<T> 类型使用
weak_count 来记录其存在多少个 Weak<T>
引用,区别仅在于 weak_count 无需计数为 0 就能使
Rc<T> 实例被清理。
强引用代表如何共享 Rc<T>
实例的所有权,但弱引用并不属于所有权关系。不会造成引用循环,因为任何弱引用的循环,会在强引用计数为
0 时被打断。
因为 Weak<T>
所引用的值可能已经被丢弃了,所以为了使用 Weak<T>
所指向的值,我们必须保证值仍然有效。可以使用 Weak<T>
的 upgrade 方法获得一个
Option<Rc<T>>。若 Rc<T>
的值未被丢弃,则结果是 Some;若已经被丢弃,则结果是
None。因为 upgrade 返回的是一个
Option<Rc<T>>,所以 Rust 可以保证
Some 或 None,不会返回非法指针。
创建树形结构
我们可以定义一个 Node 节点:
use std::cell::RefCell;
use std::rc::Rc;
#[derive(Debug)]
struct Node {
value: i32,
children: RefCell<Vec<Rc<Node>>>,
}我们希望 Node
有子节点,并通过变量来共享所有权,以便于访问树中每一个
Node,为此 Vec<T> 的类型为
Rc<Node>。我们还希望能修改其他节点的子节点,所以
children 中 Vec<Rc<Node>> 被放进了
RefCell<T>。
创建一个简单的树实例:
fn main() {
let leaf = Rc::new(Node {
value: 3,
children: RefCell::new(vec![]),
});
let branch = Rc::new(Node {
value: 5,
children: RefCell::new(vec![Rc::clone(&leaf)]),
});
}这里克隆了 leaf 中的 Rc<Node>
并储存在了 branch 中,这意味着 leaf 中的
Node 现在有两个所有者:leaf 和
branch。可以通过 branch.children 从
branch 中获得 leaf,不过无法从
leaf 到 branch。leaf 没有到
branch 的引用且并不知道他们相互关联。
增加子到父的引用
我们可以更改定义为:
use std::cell::RefCell;
use std::rc::{Rc, Weak};
#[derive(Debug)]
struct Node {
value: i32,
parent: RefCell<Weak<Node>>,
children: RefCell<Vec<Rc<Node>>>,
}父节点应该拥有其子节点:如果父节点被丢弃了,其子节点也应该被丢弃。然而子节点不应该拥有其父节点:如果丢弃子节点,其父节点应该依然存在。这正是弱引用登场的时候。
这样,一个节点就能够引用其父节点,但不拥有其父节点。
可以这样使用它:
fn main() {
let leaf = Rc::new(Node {
value: 3,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![]),
});
println!("leaf parent = {:#?}", leaf.parent.borrow().upgrade());
let branch = Rc::new(Node {
value: 5,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![Rc::clone(&leaf)]),
});
*leaf.parent.borrow_mut() = Rc::downgrade(&branch);
println!("leaf parent = {:#?}", leaf.parent.borrow().upgrade());
}输出为:
leaf parent = None
leaf parent = Some(
Node {
value: 5,
parent: RefCell {
value: (Weak),
},
children: RefCell {
value: [
Node {
value: 3,
parent: RefCell {
value: (Weak),
},
children: RefCell {
value: [],
},
},
],
},
},
)没有无限的输出表明这段代码并没有造成引用循环。这一点也可以从观察
Rc::strong_count 和 Rc::weak_count
调用的结果看出。
可视化强弱引用记数的改变
可以创建了一个新的内部作用域并将 branch
的创建放入其中,来观察 Rc<Node> 实例的
strong_count 和 weak_count 值的变化:
fn main() {
let leaf = Rc::new(Node {
value: 3,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![]),
});
println!(
"leaf strong = {}, weak = {}",
Rc::strong_count(&leaf),
Rc::weak_count(&leaf),
);
{
let branch = Rc::new(Node {
value: 5,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![Rc::clone(&leaf)]),
});
*leaf.parent.borrow_mut() = Rc::downgrade(&branch);
println!(
"branch strong = {}, weak = {}",
Rc::strong_count(&branch),
Rc::weak_count(&branch),
);
println!(
"leaf strong = {}, weak = {}",
Rc::strong_count(&leaf),
Rc::weak_count(&leaf),
);
}
println!("leaf parent = {:?}", leaf.parent.borrow().upgrade());
println!(
"leaf strong = {}, weak = {}",
Rc::strong_count(&leaf),
Rc::weak_count(&leaf),
);
}输出为:
leaf strong = 1, weak = 0
branch strong = 1, weak = 1
leaf strong = 2, weak = 0
leaf parent = None
leaf strong = 1, weak = 0一旦创建了 leaf,强引用记数就为 1,弱引用记数就为
0。在内部作用域中创建了 branch 并与 leaf
相关联,此时 branch 中 Rc<Node>
的强引用计数为 1,弱引用计数为 1(因为 leaf.parent 通过
Weak<Node> 指向 branch)。这里
leaf 的强引用计数为 2,因为现在 branch 的
branch.children 中储存了 leaf 的
Rc<Node> 的拷贝,不过弱引用计数仍然为 0。
当内部作用域结束时,branch
离开作用域,Rc<Node> 的强引用计数减少为 0,所以其
Node 被丢弃。来自 leaf.parent 的弱引用计数 1
与 Node 是否被丢弃无关,所以并没有产生任何内存泄漏。
如果在内部作用域结束后尝试访问 leaf 的父节点,会再次得到
None。在程序的结尾,leaf 中
Rc<Node> 的强引用计数为 1,弱引用计数为 0,因为现在
leaf 又是 Rc<Node> 唯一的引用了。
总结
这里总结一下这几种智能指针的常见目的:
Box<T>能够指向堆上的数据Rc<T>允许数据有多个不可变的所有者RefCell<T>使用内部可变性模型,允许在运行时检查借用,在自身不变的情况下改变其内部的值