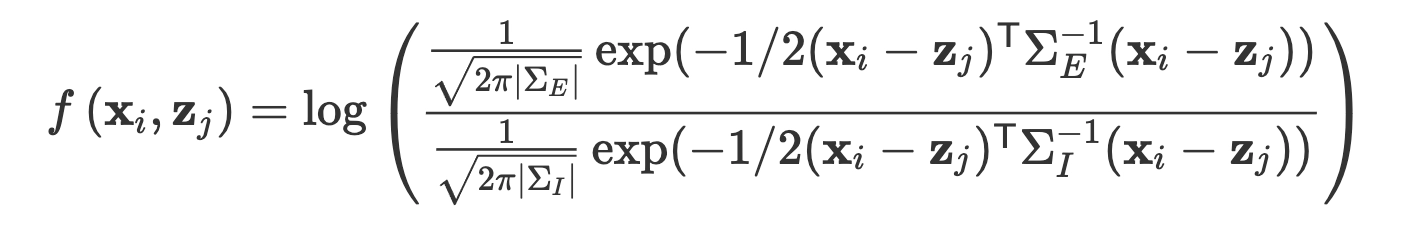
相关工作
- 马氏距离,即
Mahalanobis Distance KISSME方法1,全称Keep It Simple and Straightforward Metric即保持直接简单原则的度量方法,属于有监督的线性度量学习方法,本质上还是学习马氏距离中的矩阵 $ $XQDA+LOMO方法2,交叉视角的二次判别分析算法是基于KISSME提出的改进算法,使用LOMO特征提取的方法,再通过LDA算法投影到度量子空间用于降维,再进行马氏距离度量。
马氏距离 Mahalanobis Distance
- 标准马氏距离通过引入协方差矩阵,使得其度量出考虑属性之间相关性且尺度无关的距离
\[ d(\mathbf{x}_i, \mathbf{x}_j) = \left\| \mathbf{x}_i - \mathbf{x}_j \right\|_{\Sigma ^{-1}}^{2} = (\mathbf{x}_i - \mathbf{x}_j)^{\mathsf{T}} \Sigma ^{-1}(\mathbf{x}_i - \mathbf{x}_j) \]
- 而通用马氏距离则通过一个通用的度量矩阵 \(\mathbf{M}\),按照不同的需求和样本特征度量距离。为了保证距离度量的非负性与对称性,矩阵 \(\mathbf{M}\) 必须为半正定对称矩阵
\[ d(\mathbf{x}_i, \mathbf{x}_j) = \left\| \mathbf{x}_i - \mathbf{x}_j \right\|_{\mathbf{M}}^{2} = (\mathbf{x}_i - \mathbf{x}_j)^{\mathsf{T}} \mathbf{M}(\mathbf{x}_i - \mathbf{x}_j) \]
KISSME 方法
- 首先,认为对于样本对 \((\mathbf{x}_i,\mathbf{z}_j)\),它们之间的差异程度可以通过似然比检验来观测,构造如下似然比函数
\[f\left(\mathbf{x}_i,\mathbf{z}_j\right)=\log{\left(\frac{p\left(\mathbf{x}_i-\mathbf{z}_j|H_0\right)}{p\left(\mathbf{x}_i-\mathbf{z}_j|H_1\right)}\right)} \]
- 其中,\(H_0\) 假设为样本对不相似(即为负样本对),\(H_1\) 假设为样本对相似(即为正样本对),\(f(\mathbf{x}_i, \mathbf{z}_j)\) 值越大则 \(H_0\) 假设越符合,样本差异越大。反之,\(f(\mathbf{x}_i, \mathbf{z}_j)\) 值越小,样本差异越小。
- 假设样本差向量符合 \(0\) 均值的高斯分布,则有
\[ f\left(\mathbf{x}_i,\mathbf{z}_j\right)= \log \left( \frac{\frac{1}{\sqrt{2\pi |\Sigma_E|}} \exp (-1/2 (\mathbf{x}_i-\mathbf{z}_j)^\mathsf{T} \Sigma^{-1}_E(\mathbf{x}_i-\mathbf{z}_j))}{\frac{1}{\sqrt{2\pi |\Sigma_I|}} \exp (-1/2 (\mathbf{x}_i-\mathbf{z}_j)^\mathsf{T} \Sigma^{-1}_I(\mathbf{x}_i-\mathbf{z}_j))}\right) \]
- 将对数运算展开则有
\[ \begin{split}f(\mathbf{x}_{i}-\mathbf{z}_{j}) = {} &(\mathbf{x}_{i}-\mathbf{z}_{j})^{\mathsf{T}}\Sigma^{-1}_{I}(\mathbf{x}_{i}-\mathbf{z}_{j})+\log(\left| \Sigma^{-1}_{I}\right|)-{} \\&(\mathbf{x}_{i}-\mathbf{z}_{j})^{\mathsf{T}}\Sigma^{-1}_{E}(\mathbf{x}_{i}-\mathbf{z}_{j})-\log(\left| \Sigma^{-1}_{E} \right| )\end{split} \]
- 将只提供偏置的常数项去掉,化简得到
\[ f\left(\mathbf{x}_i,\mathbf{z}_j\right)= (\mathbf{x}_i-\mathbf{z}_j)^{\mathsf{T}}(\Sigma^{-1}_{I} - \Sigma^{-1}_{E})(\mathbf{x}_i-\mathbf{z}_j) \]
- 最后便得到了反映了对数似然比检验属性的马氏距离度量
\[d(\mathbf{x}_i, \mathbf{z}_j)=(\mathbf{x}_i-\mathbf{z}_j)^{\mathsf{T}}\mathbf{M}(\mathbf{x}_i-\mathbf{z}_j) = (\mathbf{x}_i-\mathbf{z}_j)^{\mathsf{T}}(\Sigma^{-1}_{I} - \Sigma^{-1}_{E})(\mathbf{x}_i-\mathbf{z}_j)\]
- 上述的
KISSME方法主要利用假设检验的思想,建立一个正负样本对概率的似然比函数作为统计量,使得正负样本分布服从两个不同的参数的高斯分布,学习一个马氏距离的 \(\mathbf{M}\) 矩阵。
XQDA + LOMO 方法
LOMO是一种特征提取手段,不多赘述。XQDA则在KISSME方法上更近一步,使用QDA方法,学习一个具有辨别力的子空间,然后再用马氏距离进行度量。所以重新构造似然比函数,其中 \(\mathbf{W}\) 为投影矩阵,将 \((\mathbf{x}_i,\mathbf{z}_j)\) 投影到低维度子空间。
\[f\left(\mathbf{x}_i,\mathbf{z}_j\right)=\log{\left(\frac{p\left(\mathbf{W}^{\mathsf{T}}\mathbf{x}_i-\mathbf{W}^{\mathsf{T}}\mathbf{z}_j|H_0\right)}{p\left(\mathbf{W}^{\mathsf{T}}\mathbf{x}_i-\mathbf{W}^{\mathsf{T}}\mathbf{z}_j|H_1\right)}\right)} \]
- 进行相同的化简和对数展开
\[\begin{split}f(\mathbf{x}_{i}-\mathbf{z}_{j}) = {} &\mathbf{W}(\mathbf{x}_{i}-\mathbf{z}_{j})^{\mathsf{T}}\Sigma^{-1}_{I}(\mathbf{x}_{i}-\mathbf{z}_{j})\mathbf{W}^{\mathsf{T}}+\log(\left| \Sigma^{-1}_{I}\right|)-{} \\ &\mathbf{W}(\mathbf{x}_{i}-\mathbf{z}_{j})^{\mathsf{T}}\Sigma^{-1}_{E}(\mathbf{x}_{i}-\mathbf{z}_{j})\mathbf{W}^{\mathsf{T}}-\log(\left| \Sigma^{-1}_{E} \right| )\end{split}\]
- 丢掉偏置项的常数得到
\[ f\left(\mathbf{x}_i,\mathbf{z}_j\right)= \mathbf{W}(\mathbf{x}_i-\mathbf{z}_j)^{\mathsf{T}}(\Sigma^{-1}_{I} - \Sigma^{-1}_{E})(\mathbf{x}_i-\mathbf{z}_j)\mathbf{W}^{\mathsf{T}} \]
- 利用
LDA方法的思想,对行人的分类可以表示为一个多分类的LDA投影子空间学习任务,计算类内和类间散度
\[\begin{cases} \mathbf{S}_{w} = \displaystyle\frac{1}{N}\displaystyle\sum_{i=1}^{C} \displaystyle\sum_{j=1}^{N_i} (\mathbf{y}_{i,j}-\overline{\mathbf{y}}_{i})(\mathbf{y}_{i,j}-\overline{\mathbf{y}}_{i})^{\mathsf{T}} \\ \mathbf{S}_b = \displaystyle\frac{1}{C} \displaystyle\sum_{i=1}^{C} (\overline{\mathbf{y}}_{i}-\overline{\mathbf{y}})(\overline{\mathbf{y}}_{i}-\overline{\mathbf{y}})^{\mathsf{T}}\end{cases}\]
- 建立优化模型如下
\[ \max{J}(\mathbf{w})=\frac{\mathbf{w}^{\mathsf{T}}\mathbf{S}_b\mathbf{w}}{\mathbf{w}^{\mathsf{T}}\mathbf{S}_w\mathbf{w}} \]
- 转化为广义瑞利商函数的相关性质可知,对于上述模型的最优化可以转化为如下特征根分解的问题
\[\mathbf{S}_w^{-1}\mathbf{S}_b\mathbf{w}=\lambda\mathbf{w} \]
- 求解得到的特征向量中,对应特征根值最大的特征向量对应上述优化模型的最优解 \(\mathbf{w}_1\),使得目标函数 \(J(\mathbf{w})\) 取得最大值。进一步,对应特征值第二大的特征向量 ,使得目标函数 \(J(\mathbf{w})\) 取得次优解。依次类推,对特征向量按照特征根由大到小的顺序排列,选取前 \(r\) 个向量组成投影矩阵,
\[ \mathbf{W}=\left(\mathbf{w}_1,\mathbf{w}_2,\cdots,\mathbf{w}_r\right)\]
XQDA主要通过学习一个具有辨别力的子空间,最后在使用马氏距离度量投影到子空间后的距离。
基于样本相似性和参考集约束的改进
基于正样本分布距离的约束
首先,目前模型的可以正确的识别出部分样本,并且在训练集上表现良好,只是在测试集上过拟合现象较为严重。
一个有效的度量模型,在训练集和测试集的正样本之间的距离分布应该一致。
所以我们假定数据集 \(\mathbf{A}^\prime=\left\{\mathbf{x}_1^\prime,\mathbf{x}_2^\prime,\cdots,\mathbf{x}_i^\prime,\cdots,\mathbf{x}_{N^\prime}^\prime\right\}, \mathbf{B}^\prime=\left\{\mathbf{z}_1^\prime,\mathbf{z}_2^\prime,\cdots, \mathbf{z}_j^\prime,\cdots,\mathbf{z}_{N^\prime}^\prime\right\}\) 分别表示测试数据中两个摄像头 A 和 B 中的行人图像特征集合。
基于已经训练了的
XQDA模型,在测试集 \(\mathbf{B}'\) 中寻找 \(k\) 个最相似的样本,并计算这些样本的均值,方法如下
\[ \mathbf{v}_i=\mathbf{x}_i^\prime-\mathbf{z}_i^\prime=\frac{1}{k}\sum_{i=1}^{N}{q_{ij}\alpha_{ij}\left(\mathbf{x}_i^\prime-\mathbf{z}_j\right)} \]
- 其中 \(q_{ij}\) 表示相似关系,\(\alpha_{ij}\) 表示样本对 \((\mathbf{x}_i',\mathbf{z}_j')\) 的权重,计算方法如下
\[ \alpha_{ij}=\begin{cases} 1-\frac{d(x^{^\prime}_i,z^{\prime}_j)}{\sum q_{ij}(x^{^\prime}_i,z^{\prime}_j)} & q_{ij}=1 \\ 0 & q_{ij}=0 \end{cases} \]
- 然后,计算训练集正样本差向量的分布中心
\[ \mathbf{u}=\frac{1}{N}\sum_{i=1}^{N}\left(\mathbf{x}_i-\mathbf{z}_i\right) \]
- 定义两个分布的一致性约束如下
\[ \begin{aligned} \mathbf{S} &= \frac{1}{N^\prime}\sum_{i=1}^{N^\prime}\left\| \mathbf{w}^{\mathsf{T}}\mathbf{v}_{i}-\mathbf{w}^{\mathsf{T}}\mathbf{u} \right\|_{2}^{2} \\ &=\frac{1}{N^\prime}\sum_{i=1}^{N^\prime} \mathbf{w}^{\mathsf{T}}(\mathbf{v}_{i}-\mathbf{u})(\mathbf{v}_{i}-\mathbf{u})^{\mathsf{T}}\mathbf{w} \\ &= \frac{1}{N^\prime} \mathbf{w}^{\mathsf{T}} \sum_{i=1}^{N^\prime} (\mathbf{v}_{i}-\mathbf{u})(\mathbf{v}_{i}-\mathbf{u})^{\mathsf{T}}\mathbf{w} \\ &= \frac{1}{N^\prime}\mathbf{w}^{\mathsf{T}}\mathbf{S}^\prime\mathbf{w} \end{aligned} \]
基于负样本与参考集距离的约束
我们定义一个参考集 \(\mathbf{C} = \mathbf{B}\),\(\mathbf{B}\) 为训练数据中摄像头 B 所采集的数据。
测试数据 \(\mathbf{A}'\) 中的每一个样本,与参考集 \(\mathbf{C}\) 中的每一个样本所组成的一定是负样本对。
一个有效的度量模型,\(\mathbf{A}'\) \(\mathbf{C}\) 之间负样本的距离,与测试集的负样本距离,分布应该一致。
因为测试集标签数据是不可知的,所以我们基于已经训练了的
XQDA模型,在测试集 \(\mathbf{B}'\) 中寻找 \(k'\) 以外个最不相似的样本,并计算这些样本的均值。所以我们定义参考集负样本于测试集负样本差异如下
\[ \mathbf{D} = \left\| \mathbf{w}^{\mathsf{T}}\left( \frac{1}{N_{A'} N_{C}} \sum\limits_{n=1}^{N_{A'}} \sum\limits_{j=1}^{N_C} \left( \mathbf{x}'_i - \mathbf{z}_j \right) \right) - \mathbf{w}^{\mathsf{T}}\left( \frac{1}{N_{A'}N_{B'}}\sum\limits_{s=1}^{N_{A'}} \sum\limits_{t=1}^{N_{B'}} p_{st}(\mathbf{x}_s - \mathbf{z}_t) \right) \right\|_{2}^{2} \]
其中 \(\left( \frac{1}{N_{A'} N_{C}} \sum\limits_{n=1}^{N_{A'}} \sum\limits_{j=1}^{N_C} \left( \mathbf{x}'_i - \mathbf{z}_j \right) \right)\) 为参考集的负样本对中心
\(\left( \frac{1}{N_{A'}N_{B'}}\sum\limits_{s=1}^{N_{A'}} \sum\limits_{t=1}^{N_{B'}} p_{st}(\mathbf{x}_s - \mathbf{z}_t) \right)\) 为测试集中负样本对中心
\(p_{st}\) 表示 \(\mathbf{x}_s\) 与 \(\mathbf{z}_t\) 之间的相似关系。\(\mathbf{x}_s \in \mathbf{A}', \mathbf{z}_t \in \mathbf{B}'\)
展开上式
\[ \begin{aligned} \mathbf{D} &= \left\| \mathbf{w}^{\mathsf{T}}\left( \frac{1}{N_{A'} N_{C}} \sum\limits_{n=1}^{N_{A'}} \sum\limits_{j=1}^{N_C} \left( \mathbf{x}'_i - \mathbf{z}_j \right) \right) - \mathbf{w}^{\mathsf{T}}\left( \frac{1}{N_{A'}N_{B'}}\sum\limits_{s=1}^{N_{A'}} \sum\limits_{t=1}^{N_{B'}} p_{st}(\mathbf{x}_s - \mathbf{z}_t) \right) \right\|_{2}^{2} \\ &=\begin{aligned}[t] &\mathbf{w}^{\mathsf{T}}\left( \frac{1}{N_{A'} N_{C}} \sum\limits_{n=1}^{N_{A'}} \sum\limits_{j=1}^{N_C} \left( \mathbf{x}'_i - \mathbf{z}_j \right) - \frac{1}{N_{A'}N_{B'}}\sum\limits_{s=1}^{N_{A'}} \sum\limits_{t=1}^{N_{B'}} p_{st}(\mathbf{x}_s - \mathbf{z}_t) \right) \\ &\left( \frac{1}{N_{A'} N_{C}} \sum\limits_{n=1}^{N_{A'}} \sum\limits_{j=1}^{N_C} \left( \mathbf{x}'_i - \mathbf{z}_j \right) - \frac{1}{N_{A'}N_{B'}}\sum\limits_{s=1}^{N_{A'}} \sum\limits_{t=1}^{N_{B'}} p_{st}(\mathbf{x}_s - \mathbf{z}_t) \right)^{\mathsf{T}}\mathbf{w} \end{aligned}\\ &=\mathbf{w}^{\mathsf{T}}\mathbf{D}'\mathbf{w} \end{aligned} \]
改进后的最优化模型
- 依据上述的两个约束,改进的度量模型如下
\[ \max{J}(\mathbf{w})=\frac{\mathbf{w}^{\mathsf{T}}(\mathbf{S}_b + \mathbf{D}^{\prime})\mathbf{w}}{\mathbf{w}^{\mathsf{T}}(\mathbf{S}_w+\alpha \mathbf{S}^{\prime})\mathbf{w}} \]
- 同样的,转换为如下特征根问题
\[ \left(\mathbf{S}_w+\alpha \mathbf{S}^\prime\right)^{-1}(\mathbf{S}_b + \mathbf{D}')\mathbf{w}=\lambda\mathbf{w} \]
实验
测试数据
VIPeR3 是一个基准数据集- 非重叠,不同时
- \(632\) 个目标
- \(1264\) 张图像
- \(128 \times 48\) 分辨率,不能用人脸特征
- 包含各种行人步态的变化、背景的变化、照明条件的变化和各种 拍摄角度的变化,数据集很符合实际的应用场景。
- 使用 \(50\%\) 训练集,\(50\%\) 测试集分割数据集,也就是,各 \(316\) 个目标,\(632\) 张图片。

评价指标
- 行人再试别任务中广泛使用的累计精度曲线 CMC 作为评价指标
\[\operatorname{CMC}(l)=\frac{1}{N}\sum_{i=1}^{N}{\mathbb{I}(\operatorname{rank}(P_i)<l)} \]
- 其中,\(\operatorname{CMC}(l)\) 表示排名前 \(l\) 的识别样本的累积正确率。\(\operatorname{rank}(P_i)\) 表示第 \(i\) 个测试个体对应的正样本的距离按照从小到大顺序排序后的排名 \(\mathbb{I}(\cdot)\)是符号函数。如果\(\operatorname{rank}(P_i)\)的排序结果小于\(l\),\(\mathbb{I}(\cdot)=1\);反之,则\(\mathbb{I}(\cdot)=0\)
- 简而言之,
rank n前面能识别正确的百分比,比如rank 5就是 前 \(5\) 个里面,有对的情况。
结果分析
- 使用刚刚提到
VIPeR数据进行测试,结果取 \(10\) 次平均值
精度对比

- 相较于基线算法
XQDA,提升了 \(29.63\%\),效果显著。
不同训练样本规模下的识别精度对比

- 在训练集 \(316\) 个目标,\(200\) 个目标, \(150\)
个目标都可以达到相对较高的精度,算法的识别精度的变化较小,仅仅需要少量的训练样本便能达到很高的识别精度。
- \(200\) 个目标大概
rank 1在 \(63\%\) 左右,\(150\) 个的话rank 1在 \(59\%\) 左右
- \(200\) 个目标大概
不同维度的精度对比

- 如图可以看到,使用不同维度的投影矩阵,特征维度在 \(100\) 到 \(220\) 的变化过程中,识别精度基本没有变化。说明算法对于特征维度有很高的鲁棒性。
- 投影特征维度与矩阵分解时矩阵的维度相关,矩阵越小,则对应的计算效率越高。由此可以看出,算法对于特征维度有很高的鲁棒性,对于算法实时检测有很重要的作用,尤其是在边缘计算,比如摄像头可以直接使用边缘计算芯片,实时处理好了直接发给数据中心。
样本距离分布对比
- 可以看到相较于
XQDA基线算法,优化后的算法在过拟合的问题上有显著的缓解。


M. Kostinger, M. Hirzer, P. Wohlhart, P. M. Roth, and H. Bischof. Large scale metric learning from equivalence constraints. In IEEE Conference on Computer Vision and Pattern Recognition, 2012.↩︎
Liao, S., Hu, Y., Zhu, X., Li, S.Z.: Person re-identification by local maximal occur-rence representation and metric learning. In: Proceedings of the IEEE conferenceon computer vision and pattern recognition. (2015) 2197–2206↩︎
Du, Y., Ai, H., Lao, S.: Evaluation of color spaces for person re-identification. In: Proceedings of the 21st International Conference on Pattern Recognition(ICPR2012), IEEE (2012) 1371–1374↩︎